
# 经纬度地理位置编码索引GeoHash
在某些App中的地图上查询附近的人、附近的店、附近的车……是怎么实现的?
以闲鱼筛选附近的卖家为例,闲鱼app根据交通条件、商场分布情况、住宅区分布情况综合考虑,将城市划分为一个个商圈,商品则是由用户发布的GPS随机分布在地图上的点数据。当用户处于某个商圈范围内时,app会向用户推荐GPS位于此商圈中的商品。杭州部分区域商圈划分如下图所示。
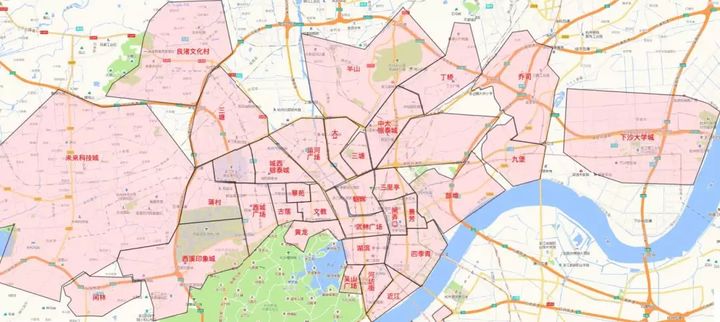
闲鱼数据库中保存有约1万多条的商圈信息和10亿条商品信息(且每天还在大量增加),如果直接使用几何学点面关系运算,需要的计算量级约为2亿亿次基本运算。按照这个思路,使用阿里巴巴集团内部的离线计算集群来执行计算,结果集群在运行了超过2天之后也未能给出结果。
有更快的方法吗?
***
现实生活中有相当一部分的地理位置数据是由经纬度数据保存的, GeoHash可以将经纬度值hash为一个**可比较的**字符串(地理编码),字符串长度和地理坐标的精度有关,地理编码越长代表划分精度越细。通过比较地点之间的地理编码值来判断它们的地位位置距离,从属关系等信息,要比直接计算球面点与点的距离快得多。
经过GeoHash改良过之后算法,闲鱼的10亿条商品数据确定商圈归属在同样的节点上面可以在一天之内给出结果。
## Geohash过程原理
假设我们现在有一个坐标点
> **常营地铁站(lat:39.9257460000, lon:116.5998310000)**
当我拿到常营地铁站的经纬度后,通过GeoHash这种算法进行计算后,获取到一个**可比较的字符串**,具体计算过程如下:
**GeoHash码从一个0-1字符串开始计算,从第第一个bit开始,对纬度进行折半细分,维度范围为[-90, 90],从最大范围开始([-90, 90]),将当前范围均分为左右两份,如果坐标纬度(39.9257460000)在左区间,则该位为0,在右区间则该位为1。然后将所在的区间范围置为当前范围,重复二分的步骤得到下一bit位。**
> 此过程可以一直重复下去,只是对维度的细分。
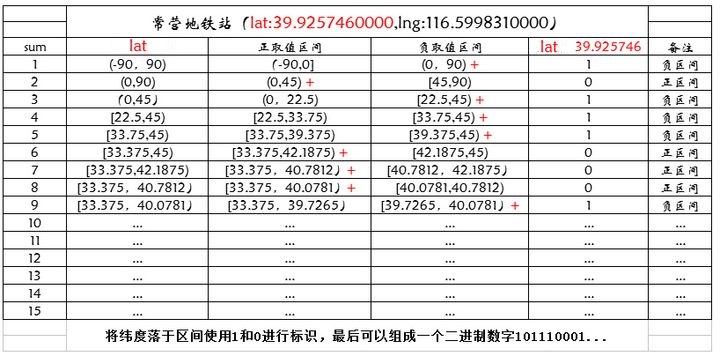
对经度的操作是同样的,二分->求bit位->二分->求bit位……
至此,我们得到了两个0-1字符串(长度任意但要是5的倍数),分别代表着坐标的经度与纬度,**将经纬度的二进制数进行组合,以奇数为纬度,偶数为经度组合,然后按5位一组将每组转换为一个十进制数(0-31),再每个十进制数转换为对应的Base-32码,就完成了对坐标的GeoHash->`wx4g0e`。**

***
## 为什么该字符串可以比较?
Geohash其实就是将整个地图或者某个分割所得的区域进行一次划分,由于采用的是base32编码方式,即Geohash中的每一个字符(如wx4g0e中的w)都是由5bits组成(2^5 = 32,base32),这5bits可以有32中不同的组合(0~31),这样我们可以将整个地图区域分为32个区域,通过00000 ~ 11111来标识这32个区域。第一次对地图划分后的情况如下图所示(每个区域中的编号对应于该区域所对应的编码,其实是Z字形划分,Z字形划分会导致相邻的GeoHash码地理位置突变的问题)。
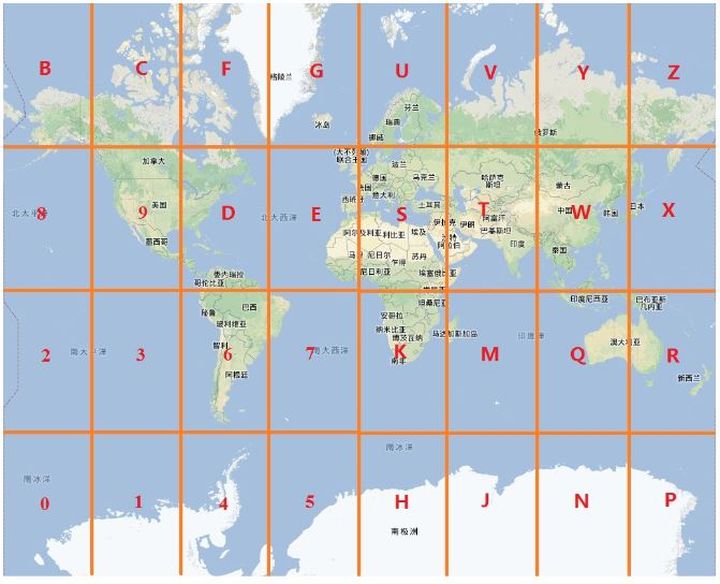
> 为什么是Base32?
因为按照经纬交叉得到的字符串经base32划分后,会将区域分为4x8共32个区域,这正好与经纬度比例[-180,180],[-90,90]相同。
当又有一位GeoHash码时,就相当于又对上图中的32个区域每个区域又以同样的方式划分成32份,每一个2位的GeoHash码对应了32x32个划分块中的一个块。我们将上图中的d和e区域再次各自按同样方法分为32块,每块就对应一个2位的geohash值(d0-dz,e0-ez),当GeoHash码字符位数足够多时,可以将地理区域分的非常精细。
> GeoHash的偶数位字符会将区域划分为8x4的块,实际上也有base64的GeoHash算法。
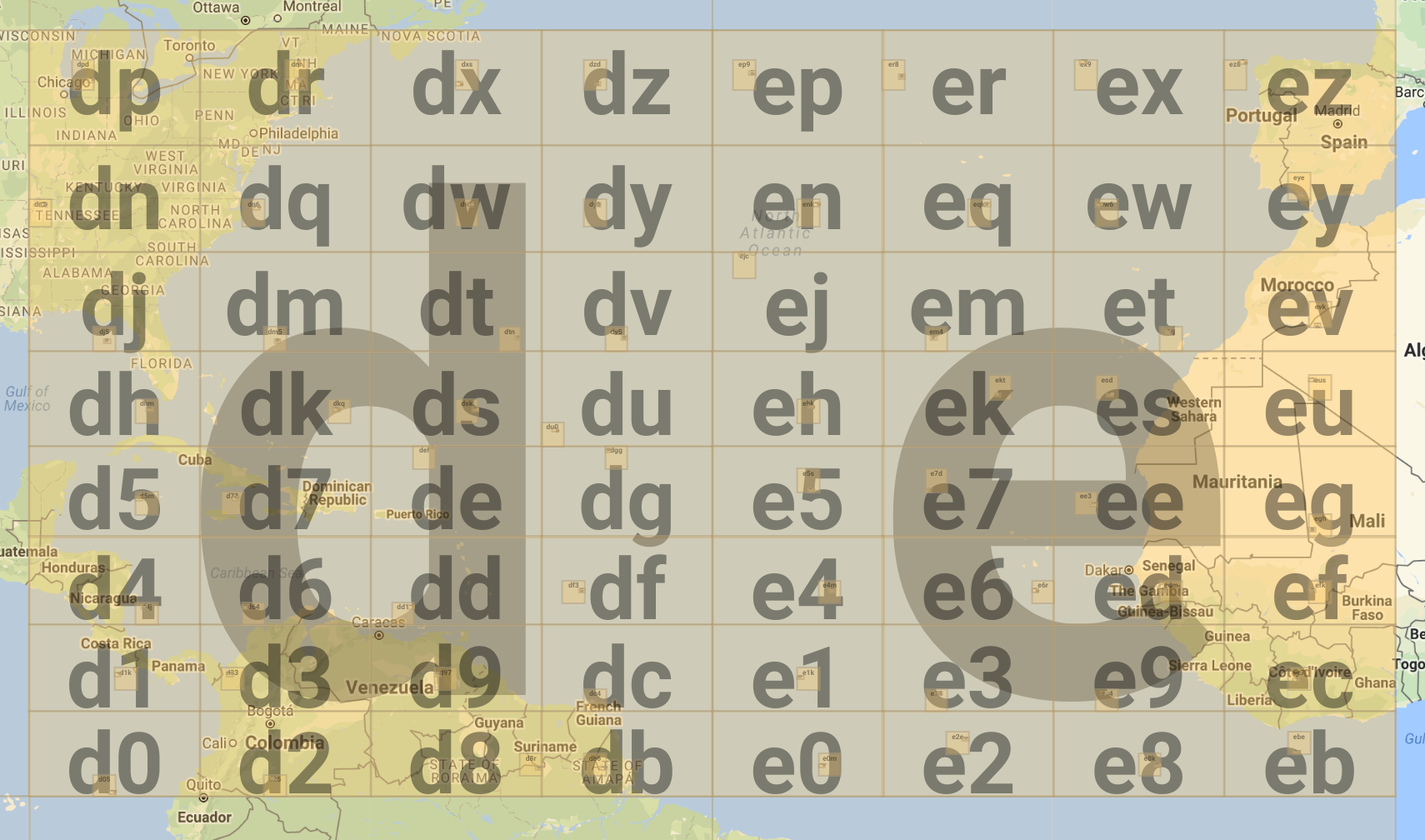
**那么,如果两个坐标GeoHash码前面几位相同就意味着两个坐标在相同的划分粒度下,被分到了同一个块里,它们可以被认为相近。**
对于文章开始的问题,我们可以通过一些方式获得商圈所对应的GeoHash值(一个或一些),用商品数据对商圈的数据在geohash值上做join,就可以得到商品所属的商圈信息。
**这里面有一个问题,有可能两个被块分开但是实际上很接近的点会被认为不相近。**
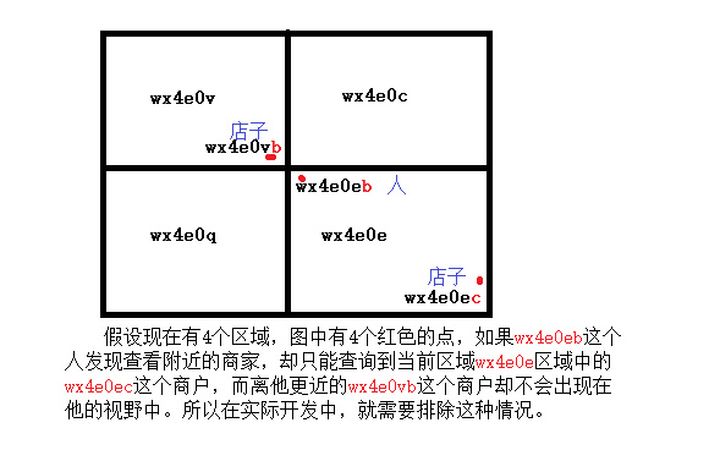
目前比较通行的做法就是我们**不仅获取当前我们所在的矩形区域,还获取周围8个矩形块中的点**。那么怎样定位周围8个点呢?关键就是需要获取周围8个点的经纬度,那我们已经知道自己的经纬度,**只需要用自己的经纬度减去最小划分单位的经纬度就行**。因为我们知道经纬度的范围,有知道需要划分的次数,所以很容易就能计算出最小划分单位的经纬度。
> 目前Redis,ClickHouse直接支持GeoHash操作
***
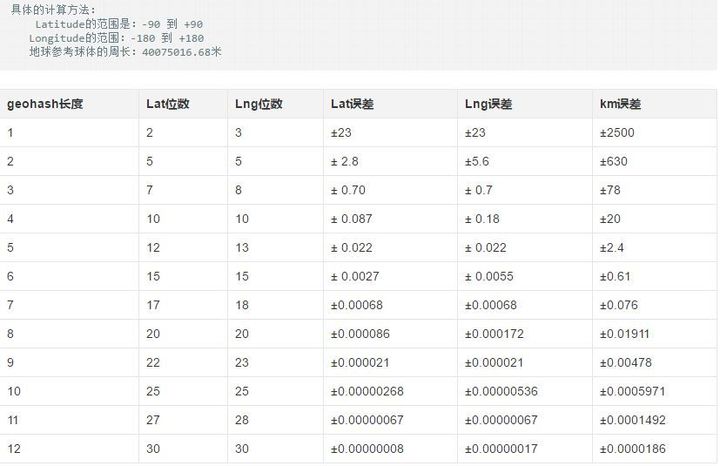
附上GeoHash长度与精度值的参考:
| 字符串长度 | | cell 宽度 | | cell 高度 |
| ---------- | ---- | --------- | ---- | --------- |
| 1 | ≤ | 5,000km | × | 5,000km |
| 2 | ≤ | 1,250km | × | 625km |
| 3 | ≤ | 156km | × | 156km |
| 4 | ≤ | 39.1km | × | 19.5km |
| 5 | ≤ | 4.89km | × | 4.89km |
| 6 | ≤ | 1.22km | × | 0.61km |
| 7 | ≤ | 153m | × | 153m |
| 8 | ≤ | 38.2m | × | 19.1m |
| 9 | ≤ | 4.77m | × | 4.77m |
| 10 | ≤ | 1.19m | × | 0.596m |
| 11 | ≤ | 149mm | × | 149mm |
| 12 | ≤ | 37.2mm | × | 18.6mm |

经纬度地理位置编码GeoHash

